会说话的电子产品总让人感觉更加‘人性化’。
让Micro:bit发声实在让人兴奋。而在Microbit中配备的从1980年早期就风靡的发声合成器,源自早期电影的机器人声音。
说说
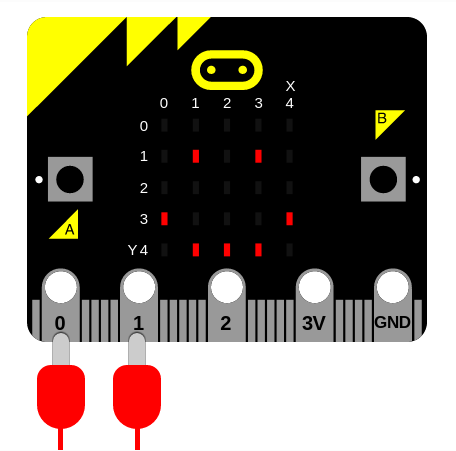
首先需要在Microbit上按下图接入扬声器:
最简单的发声办法是导入模块speech然后使用功能say:
importspeech
speech**.**say("Hello, World")
要实现更高级的发声我们需要改变合成器发声的四种参数:
pitch
是这样Speech(语音)
这个模块可以进行短距离聊天,唱歌并发出其他声音,只要您将扬声器连接到microbit。
语音合成器可以产生大约2.5秒的文本输入最多255个字符的声音。
使用该包:
import speech
以下内容默认已经导入该包。
函数
speech.translate(words)
在字符串中给出英文单词words,返回一个包含适当发音音符的最佳的字符串。可以根据下文的音符翻译表。
该功能可以用来生成一个相近的音调,可进一步手动编辑,以提高准确度。
speech.pronounce(phonemes,*,pitch=64,speed=72,mouth=128,throat=128)
在字符串中发音音素phonemes。有关如何使用音素精细控制语音合成器输出的详细信息,请参见下文。重设可选的音高,速度,口和音调,以更改语音的音质。
speech.say(words,*,pitch=64,speed=72,mouth=128,throat=128)
在字符串中说英文单词words,结果对于英语发音是有点偏差的。可以重设音高,速度,口和音调,以更改语音的音质。与以下语句等同:
speech.pronounce(speech.translate(words))
speech.sing(phonemes,*,pitch=64,speed=72,mouth=128,throat=128)
唱出字符串中包含的音素phonemes。更改音高和持续时间。重设可选的音高,速度,口和音调,以更改语音的音质。
标点
标点符号用来改变说话的方式。合成器可以理解四种标点符号:连字符、逗号、句号和问号。
连字符(-)连接两个单词,在符号处会有一个短暂的停顿。
逗号(,)标记短语边界,并插入大约两个字符的暂停。
全停(.)和问号(?)结束句。全程插入暂停,并使音高下降。问号也插入一个暂停,但会导致音高上升。这与“是我们回家吗”是否存在问题有关,而不是更复杂的问题,例如“我们为什么要回家”在后一种情况下,会使用全停。
音色
音色是声音的质量。这是机器人的声音和人的声音之间的区别。为了控制音色变化,可设置数值参数pitch,speed,mouth和throat。
音调(语音听起来的高低)和速度(语音的快慢)设置相当明显,一般分为以下几类:
Pitch(音高):
- 0-20不太可能设置为该值
- 20-30非常高
- 30-40高
- 40-50正常高
- 50-70正常
- 70-80正常低
- 80-90低
- 90-255非常低
(默认的是64)
Speed:
- 0-20不太可能设置为该值
- 20-40非常快
- 40-60快
- 60-70快速对话
- 70-75普通对话
- 75-90叙述
- 90-100慢
- 100-255很慢
(默认的是72)
mouth和throat值有点难以解释,下面的描述是基于我们每次设置的值改变后产生的语音的声音印象。
对于mouth来说,数字越少,扬声器听起来就像嘴唇说话时的幅度越小。相比之下,数字越大(最大255)听起来就像嘴唇的幅度越大。
对于throat,数字越低,说话的声音就越放松。相比之下,数字越高,语气就越紧张。
重要的是要尝试和调整这些设置,直到达到预期效果。
这里有一些例子:
speech.say("I am a little robot", speed=92, pitch=60, throat=190, mouth=190)
speech.say("I am an elf", speed=72, pitch=64, throat=110, mouth=160)
speech.say("I am a news presenter", speed=82, pitch=72, throat=110, mouth=105)
speech.say("I am an old lady", speed=82, pitch=32, throat=145, mouth=145)
speech.say("I am E.T.", speed=100, pitch=64, throat=150, mouth=200)
speech.say("I am a DALEK - EXTERMINATE", speed=120, pitch=100, throat=100, mouth=200)
Phonemes(音位)
这个say功能可以很容易地产生语音-但是通常它不准确。为了确保语音合成器能够准确地发音,您需要使用音素:可以用来区分不同单词的在听觉上不同的最小声音单位。基本上,声音都是他们构成的。
该pronounce()函数包含国际语音字母表的简化和字符串的发音以及选择需要注释的部分,以便各种发音。
使用音素的优点是您不必知道如何拼写!相反,你只需要知道如何说这个词来拼写它。
下表列出了合成器理解的音素。
SIMPLE VOWELS VOICED CONSONANTS
IY f(ee)t R (r)ed
IH p(i)n L a(ll)ow
EH b(e)g W a(w)ay
AE S(a)m W (wh)ale
AA p(o)t Y (y)ou
AH b(u)dget M (S)am
AO t(al)k N ma(n)
OH c(o)ne NX so(ng)
UH b(oo)k B (b)ad
UX l(oo)t D (d)og
ER b(ir)d G a(g)ain
AX gall(o)n J (j)u(dg)e
IX dig(i)t Z (z)oo
ZH plea(s)ure
DIPHTHONGS V se(v)en
EY m(a)de DH (th)en
AY h(igh)
OY b(oy)
AW h(ow) UNVOICED CONSONANTS
OW sl(ow) S (S)am
UW cr(ew) SH fi(sh)
F (f)ish
TH (th)in
SPECIAL PHONEMES P (p)oke
UL sett(le) (=AXL) T (t)alk
UM astron(om)y (=AXM) K (c)ake
UN functi(on) (=AXN) CH spee(ch)
Q kitt-en (glottal stop) /H a(h)ead
以下非标准符号也可供用户使用:
YX diphthong ending (weaker version of Y)
WX diphthong ending (weaker version of W)
RX R after a vowel (smooth version of R)
LX L after a vowel (smooth version of L)
/X H before a non-front vowel or consonant - as in (wh)o
DX T as in pi(t)y (weaker version of T)
这里有一些很少使用的音素组合:
PHONEME YOU PROBABLY WANT: UNLESS IT SPLITS SYLLABLES LIKE:
COMBINATION
GS GZ e.g. ba(gs) bu(gs)pray
BS BZ e.g. slo(bz) o(bsc)ene
DS DZ e.g. su(ds) Hu(ds)son
PZ PS e.g. sla(ps) -----
TZ TS e.g. cur(ts)y -----
KZ KS e.g. fi(x) -----
NG NXG e.g. singing i(ng)rate
NK NXK e.g. bank Su(nk)ist
如果你要使用除上述音素之外的其他符号,将会报ValueError异常。可以用这样的字符串传递音素:
speech.pronounce("/HEHLOW") # "Hello"
音素被分为两大类:元音和辅音。
元音被进一步细分为简单的元音和双元音。简单的元音不会改变发音,而双元音的开头是一个声音,结尾是另一个。例如,当你说“oil”这个词时,“oi”元音开头是一个“oh”音,但是变成了一个“ee”音。
辅音也分为两组:有声和无声。声音辅音要求演讲者使用他们的声带来产生声音。例如,像“L”,“N”和“Z”这样的辅音是有声的。清音辅音是通过冲击空气产生的,如“P”,“T”和“SH”。
一旦习惯了,音素系统很容易。开始一些拼写可能看起来很棘手(例如,“冒险”中有一个“CH”),但规则是写你所说的,而不是你拼写的。实验是解决有问题的单词的最佳方式。
声音听起来很机械式,这是可以理解的。为了帮助提高口语输出的质量,使用内置的压力系统增加拐点或强调,效果往往还不错。
有由数字表示8个应激标志物1-8。只需在元音后插入所需的数字即可。例如,当“/ HEHLLOW”被表达时,缺少“/ HEHLOW”的表达方式有很大的改进(和更友好)。
也可以通过强调的方式来改变词语的含义。考虑一下这句话:“为什么要走到商店?”。它可以以几种不同的方式发音:
# 你需要一个理由去做
speech.pronounce("WAY2 SHUH7D AY WAO5K TUX DHAH STOH5R.")
# 你不情愿去
speech.pronounce("WAY7 SHUH2D AY WAO7K TUX DHAH STOH5R.")
# 你想要别人这样做
speech.pronounce("WAY5 SHUH7D AY2 WAO7K TUX DHAH STOHR.")
# 你宁愿开车
speech.pronounce("WAY5 SHUHD AY7 WAO2K TUX7 DHAH STOHR.")
# 你想走在别的地方
speech.pronounce("WAY5 SHUHD AY WAO5K TUX DHAH STOH2OH7R.")
简单来说,演讲中的不同压力创造出更加表现力的语气。
他们通过提高或降低音调和延长相关元音的声音,取决于您提供的数字:
- 情绪非常紧张
- 压力非常大
- 相当强的压力
- 普通压力
- 紧张的压力
- 中性(无音调变化)
- 降低压力
- 极度降低压力
数字越小,重点越强烈。然而,这种压力标记将有助于正确地发音难点。例如,如果一个音节没有被充分发音,则放在一个中性的压力标记中。
还可以用压力标记来伸长单词:
speech.pronounce("/HEH5EH4EH3EH2EH2EH3EH4EH5EHLP.”)
Singing(唱歌)
可以使MicroPython唱歌的音素。
这是通过在音素上注释音高相关号来完成的。数字越小,音高越高。数字大致翻译成音符,如下图所示:

通过在一个哈希表和音素前面预先注释(#)音调数来工作。音高将保持不变,直到给出新的注释。例如,使MicroPython唱这样音调:
solfa = [
"#115DOWWWWWW", # Doh
"#103REYYYYYY", # Re
"#94MIYYYYYY", # Mi
"#88FAOAOAOAOR", # Fa
"#78SOHWWWWW", # Soh
"#70LAOAOAOAOR", # La
"#62TIYYYYYY", # Ti
"#58DOWWWWWW", # Doh
]
song = ''.join(solfa)
speech.sing(song, speed=100)
为了在一定时间内唱一首音符,可以通过重复的元音或语音辅音音素来延长音符(如上例所示)。注意,要把它们扩展到它们的组成部分。例如,“OHOHIYIYIY”可以扩展为“OY”。
工作原理
原手册是这样解释的:
首先,我们只是存储频谱,而不是记录实际的语音波形。通过这样做,我们可以节省记忆,并获得其他优势。第二,存储一些关于时间的数据。这些是与不同情况下每个音素的持续时间有关的数字,还有一些关于转换时间的数据,所以我们可以知道如何将音素混合到周围。第三,我们制定了一套规则来处理所有这些数据,令我们惊奇的是,我们的电脑发音都是很乱的。 ———————————————————————————————————————S.A.M.用户手册
输出通过audio模块提供的功能,而且,我们有一个说话的microbit。
Example(示例)
import speech
from microbit import sleep
# The say method attempts to convert English into phonemes.
speech.say("I can sing!")
sleep(1000)
speech.say("Listen to me!")
sleep(1000)
# Clearing the throat requires the use of phonemes. Changing
# the pitch and speed also helps create the right effect.
speech.pronounce("AEAE/HAEMM", pitch=200, speed=100) # Ahem
sleep(1000)
# Singing requires a phoneme with an annotated pitch for each syllable.
solfa = [
"#115DOWWWWWW", # Doh
"#103REYYYYYY", # Re
"#94MIYYYYYY", # Mi
"#88FAOAOAOAOR", # Fa
"#78SOHWWWWW", # Soh
"#70LAOAOAOAOR", # La
"#62TIYYYYYY", # Ti
"#58DOWWWWWW", # Doh
]
# Sing the scale ascending in pitch.
song = ''.join(solfa)
speech.sing(song, speed=100)
# Reverse the list of syllables.
solfa.reverse()
song = ''.join(solfa)
# Sing the scale descending in pitch.
speech.sing(song, speed=100)